Computer Science 161
Midterm Exam
March 10, 2015
82 minutes/82 points
Instructions
The points allocated to each problem correspond to how much time
we think the problem should take.
Please send your answers to me (margo@eecs.harvard.edu)
in a PLAIN TEXT file named your-lastname.txt
as an attachment - with the string "your-lastname" replaced with your
last name.
Please do not put your name at the top of your exam (as you'll
see below I would like your name at the bottom).
In a perfect world, your text file will not have lines longer than 80
characters, but I'll reformat it if it does, albeit sadly.
Label the answers clearly so it is
obvious what answers correspond to what questions. Please place
your answers in order in the file. When you have completed the
exam, please email it to
me (margo).
This exam is open text book, open source code, open notes, and open
course web site. You
may not use computers (cell phones, PDAs, or any other device that can
talk to a network)
during the exam (other than to record your answers, to view OS/161
or System/161 code or documentation, or to examine your notes or the
course web site).
You must complete the exam on your own, without assistance.
Exam Policy Statement
At the end of your exam, assuming you have followed the rules of the exam,
please write the following statement and
then place your name after it, asserting that you have followed the
rules of the exam. "I have neither given nor received help on this exam,
and I have not used any disallowed materials in the completion of this exam."
1. True False (20 points)
Answer true if the statement is always true; otherwise answer false.
If you feel that there is ambiguity and that affects your answer, feel
free to explain your logic.
- A uniprocessor with only single-threaded processes does not need
synchronization.
False:
Processes can still share resources (e.g., memory) and need
to synchronize and the OS still needs to synchronize with
devices.
- Threads waiting on a CV will be granted the CV lock on a FIFO basis.
False: There is no guarantee on how threads waiting on
a CV will be scheduled.
- If a processor supports virtual memory, then it must have a TLB.
False: you could have a processor that knows how
to traverse page tables in HW and then you might not have a TLB.
- A drum served the same purpose as modern day harddrives.
True
- The job of the operating system has always been to allow the
hardware to be used as efficiently as possible.
False: sometime we sacrifice hardware efficiency to
make people more efficient (think timesharing).
- Operating systems as an area of intellectual investigation arose in
the 60's when it was an open question whether one could construct a layer
of software that allowed hardware to be used efficiently.
True
- Most of the types of problems identified in early operating systems
have been solved today.
False: It is surprising how many of the problems
we are trying to solve today are identical to those from the 60's!
- Loadable kernel modules are the modern-day solution to extensible
operating systems, providing all the features that were desired by
the extensible OS community.
False: They are, in fact, the solution adopted; while they
solve extensibility they don't provide the safety properties researchers were
seeking -- turns out people didn't care so much.
- The transition from user mode to supervisor mode requires hardware support.
True
- It is possible to handle page faults without hardware support.
We gave credit for both T/F -- while you can do it using
two processors instead of explicit page fault support, the second processor
is, in fact, hardware
2. Short Answer & Multiple Choice (24 points)
Answer the following questions in as few sentences as necessary.
- (5 points) On a trap, what information must the kernel save or figure out.
- Must know location of the trap (PC)
- Must know address for a memory trap (Address)
- Must know if you were in kernel mode
- Must know the state of interrups
- Must know what kind of trap was encountered
- Save user registers
- Find kernel stack
- (5 points) You have been asked to design a TLB for a new processor. Your
manager would
like to understand the tradeoffs involved in deciding whether to implement
a 2-way set associative TLB or a 16-way set associative TLB. What do you tell
him/her? Which would you advise selecting for the design. (Assume that both
TLBs will hold exactly the same number of mappings.)
- A 2-way set associative TLB:
- is going to require a lot less hardware.
- is probably going to allow a shorter cycle time
- A 16-way set associate TLB:
- will probably be able to avoid thrashing under all circumstances
- with 16 entries, the replacement policy might actually matter,
while with only 2 entries it probably doesn't.
Unless they have a good reason, 16 seems like overkill
- (5 points) Jack and Jill are arguing about page replacement schemes.
One of them
claims that MRU -- replacing the most recently used page would be a
monumentally stupid replacement policy. The other argues that if you
focus only on data pages, then there are
workloads for which it would be optimal. What do you think?
If you are sequentially accessing something larger than memory,
MRU produces ideal replacement.
- (5 points) You are writing a C program and you've created a nice
clean design with a reasonably short main program and a small library
implemented in a separate file.
You want functions in both files to share a common, global debug
parameter, so you put:
extern int debug;
in both files. Each file compiles cleanly by itself, but when you go to
build your program, you get the error:
Undefined symbols for architecture x86_64:
"_debug", referenced from:
_main in foo.o
Why are you getting this error? Explain this first in high level terms
and then in lower level detail referring to the various segments in
which the debug variable is/is not defined.
You have declared that there exists a variable debug, but you never actually
allocated space for it (defined it) -- each file thinks that it's going to be
allocated somewhere else, but it never is. So, in both main and the library .o
file you've got a symbol in the cross references section for debug, but when
you link the two files together, you never find a reference to it in
the symbol table.
- (2 points) Which is true of a modern operating system kernel
(select only one):
- The kernel code is always executing.
- The kernel only stores resource state, it does not execute code.
- The kernel code executes when the kernel process is scheduled.
-
The kernel code executes in response to hardware interrupts and system calls.
- None of the above
- (2 points) You have a bunch of CS161 students who are frantically
writing code and periodically compiling it while the CS205 students
are running a bunch of long simulations.
Which scheduling algorithm would be best for the workload described?
(select only one):
- FCFS
- Lottery Scheduling
- MLFQ
- Round Robin
3. Synchronization (20 points)
For each synchronization problem described below, select the best
synchronization primitives to solve the problem. You may use each
primitive as many times as you need to. Briefly (1-2 sentences),
explain why you chose the primitive you did. Select the synchronization
primitive from the following list:
- Counting semaphore
- Binary semaphore
- Lock (w/out a CV)
- Lock and condition variable
- A common problem in soccer collisions between players jumping for
headers (this often leads to concussions). They've decided that clever
CS161 students could easily solve this problem with a synchronization
primitive that would arbitrate which player got to jump up for the header
(such primitives would have to be very high performance). Which primitive
would you suggest?
Lock -- this is classic mutual exclusion and you want the same entity to
unlock the resource that locked it, so a lock is better than a binary
sempahore.
- Professor Seltzer was making pancakes for hungry teenagers. The pancakes
come out in batches of three. She'd like a synchronization primitive that
would allocate pancakes to teenagers without fighting. (There is no need
to worry about leftovers between batches -- all pancakes are consumed
pretty much instantly.) Suggestions?
Counting semaphore: we just need to let enough teenagers through to match
the number of pancakes.
- You are competing in a new Olympic event called a distributed relay.
One team member has to run one lap at the Harvard track. The next team
member must run a lap at the Yale track. The third team member runs a lap
at Brown track and the last team member runs a lap at the Columbia track.
Each runner must not start until the previous runner has completed
his/her lap. Natually, the traditional passing of the baton or slapping of
the hands won't work, so they've turned to you, as a savvy CS161 student, to
provide the proper synchronization. What mechanism do you use?
Binary semaphore (at each handoff site) -- this is a classic case of using
a binary semaphore to schedule. The problem with a lock and CV is that it
is inefficient -- if you use 1 CV, then you have to broadcast to make sure
that runners run at the right time; if you use multiple CVs then you're using
a much heavier weight mechanism (lock+CV) when a simpler one (single semaphore)
would work.
- Competition for parking in Cambridge has become brutal due to the
massive quantities of snow accumulating on our streets. The traditional
use of space-savers (things like cones or lawn chairs that mark a spot
as being "owned" because someone invested the physical labor in shoveling
it out) has become too contentious and the Cambridge Department of Public
Works is looking for a better solution. They've decided to have neighborhoods
hand out parking tokens and any car without a visible token will be towed
to the far reaches of the universe. Each neighborhood has a token checkin
point and cars must drive to the checkin point to obtain a token for a
specific spot and return a token when they leave a spot (cars that do
not return tokens within seven minutes of leaving a spot are subject
to enormous fines). They would like the checkin points to operate as
efficiently as possible, allocating and deallocating spots in parallel
as much as possible. What synchronization primitive(s) should they use?
You need a lock and CV here (one pair for each neighborhood) --
you need to allocate specific parking spots,
so you have some shared state that tells you what spots are available and you
need a blocking mechanisms in case a car arrives when all the spots are full.
- It is well known that graduate students (as well as many others) are
motivated by free food. After the first couple of years (once classes
are complete), a graduate student's day consists mostly of doing research
and periodically checking email to determine if anyone has announced any
free food lately.
Unfortunately, the better research is going, the less likely students
are to check email, and by the time they get to the location of the free
food, it's often gone. (While they could configure their mail to alert
them every time a new message comes in, most messages do not concern free
food, so this would be quite distracting.)
There must be a better way -- can you propose use of a synchronization
primitive that would let them receive/see messages only when they
concerned free food?
This is another Lock + CV problem. Students want to block (do research)
until food becomes available.
4. Virtual Memory (18 points)
Open RISC is a specification for a family of open-source, synthesizable RISC
microprocessor cores. The OpenRISC 1000 MMU supports:
- Both 32-bit and 64-bit address spaces.
- Multiple page sizes.
- Hardware support for page tables.
- Context IDs (CID) that allow multiple processes to be translated by the
hardware without changing hardware registers.
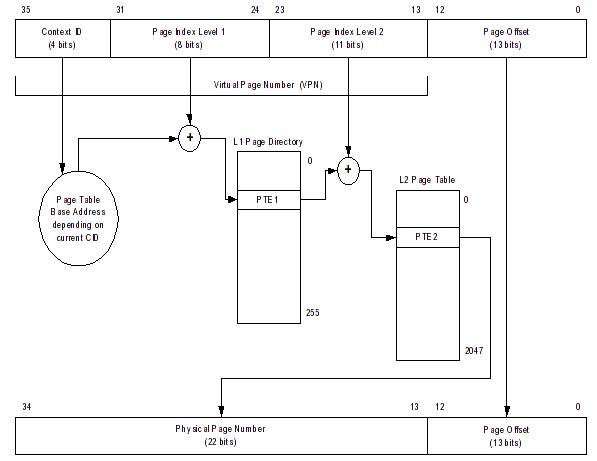
32-bit address translation takes place as follows (depicted below):
- We form a 36-bit address by prepending the process's address with
a four bit context ID.
- The top 23 bits of the 36-bit address form the virtual page number.
- The low 13 bits are the page offset.
- The CID and level 1 page index are used to index into an L1
Page Directory.
- The physical page number from the L1 Page Directory is added to the
level 2 page index to form an index into the L2 Page Table.
- The physical page number from the L2 PTE is concatenated with the page
offset to form a phyiscal address
 A page table entry is as shown:
A page table entry is as shown:

where:
- Bits 0-3 indicate cache behavior (you can ignore them)
- Bit 4 is an accessed (use) bit.
- Bit 5 is a dirty bit.
- Bits 6-8 indicate the page protection.
- Bit 9 is a link bit and can be ignored for now.
- Bits 10-31 are the physical page number.
- (2 points) What is the smallest page this architecture supports?
8K, 2^13
- (2 points) The hardware allows for treating this as a segmented
architecture by ignoring the L2 page tables. In such a configuration,
how large are segments?
2^24 = 16 MB
- (2 points) What is the largest physical address you can construct
using segments?
If you were using segments, then you could have a 22-bit page
number from the TLB attached to a 24-bit offset for a 46 bit physical address.
- (4 points) There are only 4 bits of Context ID -- is it possible to run
more than 16 processes on this architecture? If so, how?
Yes -- you would have to
- select a process whose CID you would reassign.
- Save it's L1 page table somewhere
- Copy a new process's L1 page table into place
- (4 points) Although OpenRISC provides hardware support for page
tables, it also allows software management. Name one thing that you
could do using software management that you cannot do in the hardware.
- You would not need to layout the 16 "in-context" process L1 tables contiguously.
- You could have different sizes for the two levels of page table -- if you wanted
only a few segments and then wanted to partially use them, that might let
you use memory more efficiently.
- You would not need to fully populate any page table you were using (because you
could maintain a bounds).
- If the architecture supported it, you could throw away some of the cache bits
and have larger physical addresses.
- (4 points) Knowing only what you know about this architecture, how
would you propose dealing with the operating system's memory management?
Would you run it mapped? Unmapped? Why?
Since the instructions didn't say anything about address ranges that specify
mapped versus unmapped translations (as the MIPS has),
I would probably just allocate one context ID for the
kernel (CID = 0) and run it mapped.
When I started up, it's possible that I might have to allocate specific
regions of physical memory to interact with hardware devices.